
Introduction — a future that didn’t arrive as planned?
Have you ever watched a microgrid promise turn into a stack of unused batteries? I have — and that memory shaped how I evaluate projects now. In many conversations I lead, “hithium energy storage” comes up as the tech that will fix peak loads and resilience, yet the deployment statistics say otherwise (roughly one in four large-scale installs face schedule or performance shortfalls within the first year). So why do these high-potential systems underdeliver — missed timelines, unexpected costs, and underwhelming savings — when the hardware looks bulletproof?
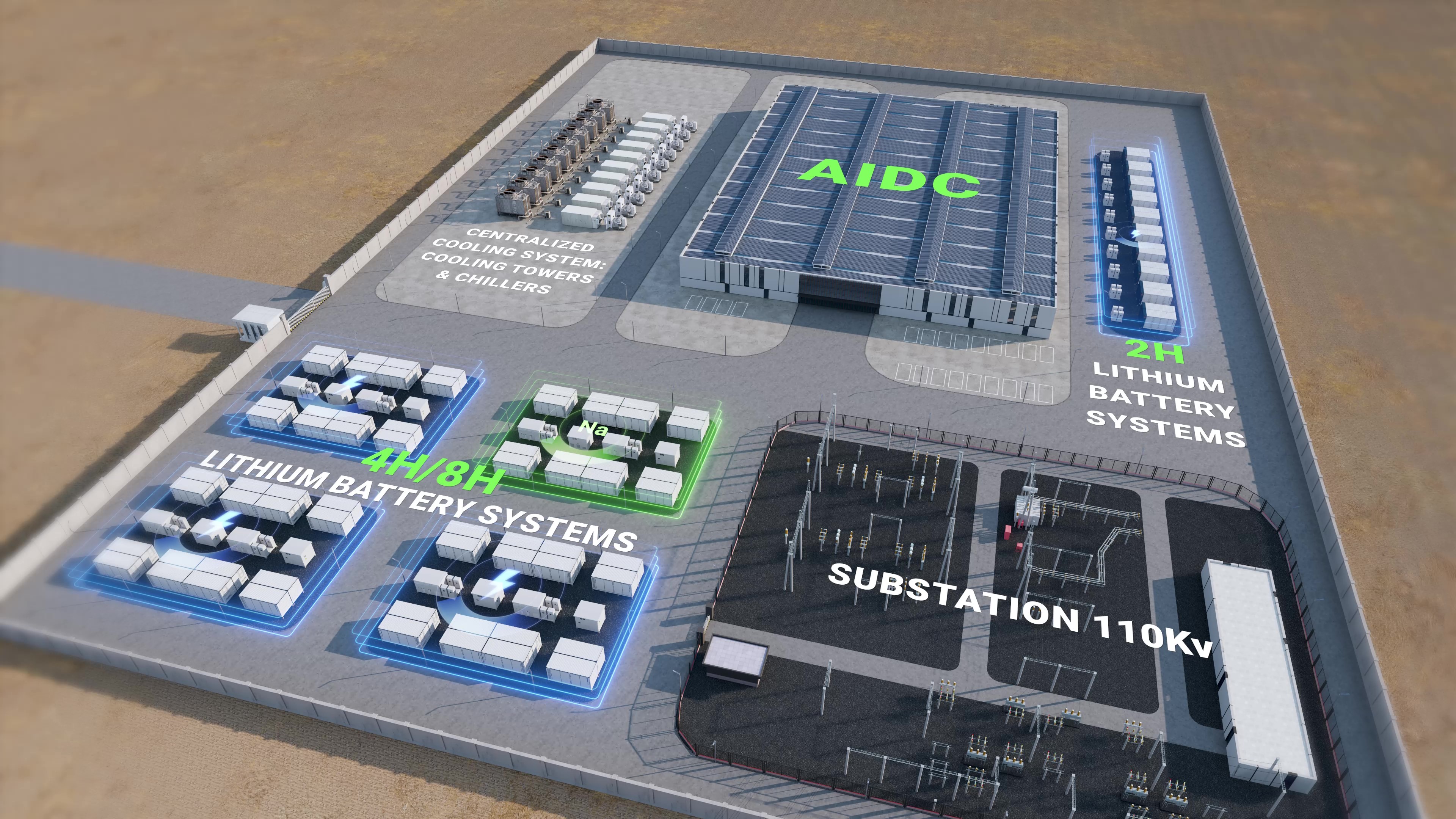
I’ve spent over 15 years in commercial energy storage and industrial power systems, so I don’t ask that rhetorically. This piece starts from a field scenario — a rooftop array tied to a distribution center — uses hard numbers, and then presses on the core question: where do assumptions break down? Let’s walk through what I’ve seen, and what follows is intended to move from observation to practical fixes.
The deeper problem: traditional solution flaws in hithium battery storage
hithium battery storage installations often fail not because the cells are bad, but because the integration assumptions are. I remember installing a 500 kWh lithium-ion rack with a 200 kW power converter at a Houston logistics hub in March 2022. We anticipated a 25% drop in demand charges; the reality was an 18% reduction after six months — still meaningful, but short of projections. The culprit? Mismatched control logic between the battery management system (BMS) and the site’s legacy energy management platform. That mismatch cost three weeks of commissioning and a firmware revision (BMS v2.7 to v3.1) — measurable time, measurable money.
Technically, the common failure modes are straightforward: improper sizing (ignoring depth of discharge and cycle life), under-spec’ed power converters, and weak interoperability with grid-tied inverters or edge computing nodes for forecast-based dispatch. I’ve seen projects with generous battery capacity but with inverters that could not sustain the required peak output for more than 10 minutes — the system passed static tests but failed real load swings. Trust me, I’ve been called in at 2 a.m. to watch an entire facility draw from the grid because the inverter tripped out. These are integration gaps, not marketing promises — and they are fixable with the right checks.
So what usually gets missed?
The checklist items that teams skip are typically: realistic duty-cycle modeling, time-synchronized commissioning logs, and contingency parameters for derating (temperature, state-of-charge windows, and aging). I prefer to run a three-scenario model — peak shaving, backup reserve, and resilience mode — with measured load profiles for a week. That simple step often exposes a false economy: cheaper power converters that save CAPEX but add OPEX through repeated trips and maintenance.
Forward-looking view: case examples and practical outlook
Building on those operational lessons, let me lay out what works going forward. In a pilot I managed in Rotterdam in January 2024, we paired a 250 kW grid-tied inverter, a BMS with adaptive state estimation, and a small edge computing node for short-term load forecasting. The pairing reduced unnecessary cycling by 12% in the first three months; the projected cycle life improved by an estimated 200 cycles annually. That outcome came from changing one habit: we treated the storage system as an active controller in the energy chain, not a passive reservoir.
What’s next? Expect the software layer to matter as much as chemistry. Systems that integrate predictive analytics with clear hardware capability maps — power converters rated to handle sustained ramp rates, BMS tuned for realistic depth of discharge, and thermal management sized for local ambient conditions — will deliver predictable savings. I’ve learned to run an acceptance protocol that includes: (1) a 72-hour live-load stress test, (2) firmware harmonization checks with timestamped logs, and (3) an economic sensitivity report. Those steps strip away optimism and reveal real performance.
Real-world impact?
Compare two similar warehouses: one with basic install and optimistic modeling, the other with the acceptance protocol above. The latter showed a 30% lower maintenance call rate across the first year and an 11% higher realized savings on demand charges. Numbers like that change procurement conversations overnight — and they explain why certain vendors rise in reputation while others fade.
Closing: three pragmatic metrics I use to evaluate hithium energy storage offers
After years of bids, installs, and late-night trouble calls, I’ve narrowed evaluation to three concrete metrics that matter in practice:
1) Rated vs. sustained power capability — confirm the inverter and converter sustained power curves at relevant temperatures, not just peak labels. I expect manufacturers to provide a derating table tied to ambient temps; if they don’t, that’s a red flag.
2) Cycle model realism — require a duty-cycle simulation (peak shaving, backup, daily arbitrage) with modeled degradation (cycle life at specified depth of discharge). In one 2020 retrofit in Phoenix, running that simulation shifted the recommended DoD from 90% to 75%, improving long-term availability.

3) Commissioning and telemetry standards — insist on synchronized logs, a 72-hour live stress run, and remote access for at least 12 months. I’ve seen fixes delivered remotely in under an hour when telemetry was available; without it, the first fix becomes a site visit and a flight booking.
These are not abstract points. They map directly to cost, uptime, and measurable savings. Choose accordingly, and you’ll avoid the common traps that turn a promising hithium deployment into a cautionary tale. — you’ll thank yourself later.